|
|
Spanish Learner Oral Corpus |
|
||
| Information | Interviews | Errors | Search | Help |
|
|
||||
1. Objectives
The aim of collecting a spoken learner corpus of Spanish as a foreign language is the error analysis of the oral production.
This research intends to improve the teaching of Spanish to foreign students by considering the errors and difficulties of every group of learners with the same L1.
2. Participants
Participants were forty (N = 40) learners of Spanish at A2 and B1 levels (CEFR). They participated in the ERASMUS programme or other international exchange agreements.
Most learners were enrolled at the Language service (Servicio de Idiomas) at the Autonomous University of Madrid (Universidad Autónoma de Madrid). Few of them were enrolled at the Complutense University of Madrid (Universidad Complutense de Madrid).
12 men and 28 women were interviewed, and most of them were between 20 and 25 years old. More information is shown in the table below.
3. Typology of the mother tongues
Four participants (N = 4) were interviewed for each of the nine groups of mother tongues (henceforth, L1). L1 typology is shown in the illustration below.

A mixed group of four students had different L1s: Korean, Finnish, Hungarian, and Turkish.
4. Recordings and data
The interviews were collected with a TASCAM© DAT (Digital Audio Tape) recorder with two microphones, and an Edirol© (Roland) digital recorder.
Recordings were digitized with a sampling rate of 16 kHz (16 bits), enough to preserve the quality of the human voice. In this interface, the format of the sound files is MP3 in order to enhance the compression of the data.
Some recordings were edited to amplify the volume, or to eliminate fragments with excessive noise. Personal information that was considered inappropriate was also deleted.
In each interview, the learner knew that he/she was being recorded. That could have affected the oral fluency, especially in the case of the shyest learners.
The length of each recording is about 15-20 minutes. Approximately, more than one hour was recorded for every group of learners with the same L1.
Overall, a total of 13 hours and 36 minutes were recorded.
The table below shows the corpus data.

*Level according to the Common European Framework of Reference for languages.
5. Design of the interview
The interview was a semi-spontaneous dialogue between the researcher and the learner. It had the following parts:
Learner's introduction.
A story-retelling task with pictures.
The illustrations of the story were those used in the exams for Diplomas of Spanish as a Foreign Language (Diploma de Español como Lengua Extranjera, or DELE). They were taken from the following book: Alzugaray, P., M. J. Barrios and C. Hernández (2006) Preparación al Diploma intermedio Español Lengua Extranjera. 1st edition. Madrid: Edelsa.
Besides the narrative tasks, learners had to express two speech acts. In one story (figure below), the participant had to express a suggestion or a proposal.

In the other story (figure below), the participant had to make a request.

Description of two photographs.

Make opinions about food and eating habits nowadays.
The final part of the interview was aimed at obtaining more spontaneous speech.
The conversation revolved around food related topics: e.g. differences between Spanish food and that of the learner's country, eating habits, the influence of diet in health, etc.
6. Transcription conventions
The interviews were manually transcribed using marks to register phenomena from speech (dysfluencies, pauses, repetitions, etc.).
The transcription conventions are an adaptation of the CHAT transcription format (as it was used in the C-Oral-Rom project; Cresti and Moneglia, 2005) and the conventions used in the SPLLOC project (Mitchell et al., 2008).
A brief summary with examples can be read here.
Any personal information related to learners' identity was anonymized in order to preserve participants' anonymity.
7. Error tagging
The errors were been tagged according to a typology based in previous Error Analysis studies for English (James, 1998; Granger, 2003; Nicholls, 2003) and Spanish (Fernández, 1997; Bustos Gisbert, 1998; Vázquez, 1999).
The information and the criteria to classify the errors is explained below:
Part of speech, syntactic group or Phonological element (segment or suprasegmental): the classification is as follows:
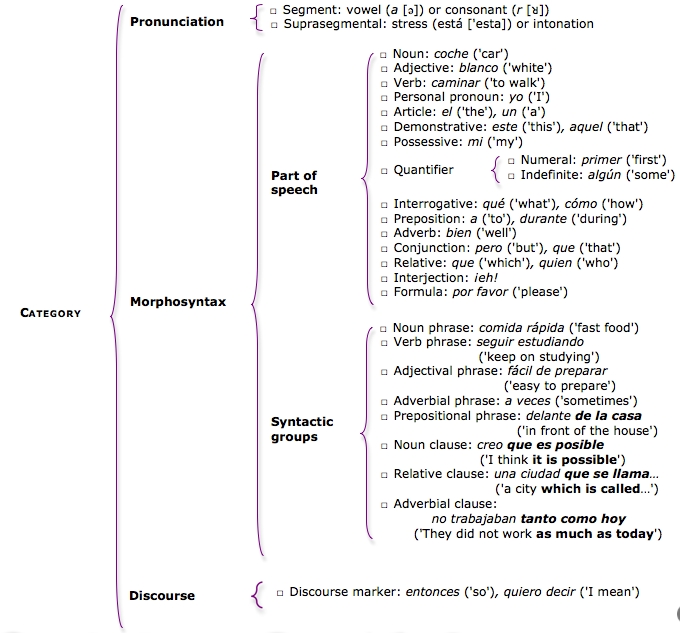
|
Target modification: the classification is the following:

|
Linguistic level: Pronunciation, Grammar, Lexis-semantics, and Pragmatics-discourse.
Type of error: the following is the classification at each linguistic level:
|
|
Etiology: intralinguistic, interlinguistic, or unknown.
Correction.
Non-ambiguous errors and ambiguous errors were distinguished. An example of an ambiguous error could be: "en [in]" (it could be a mispronunciation, but also a wrong form).
8. Word counts and frequency lists
Word counts and number of lexical units
List of lemmas (ordered by frequency)
Use of morphological categories
9. References
Alzugaray, P., M. J. Barrios, and C. Hernández (2006) Preparación al Diploma intermedio Español Lengua Extranjera. 1ª edición. Madrid: Edelsa.
Bustos Gisbert, J. M. (1998) "Análisis de errores: problemas de categorización". Dicenda: Cuadernos de filología hispánica, nº 16, págs. 11-40. Accesible en: http://revistas.ucm.es/fll/02122952/articulos/DICE9898110011A.PDF
Corder, P. (1971) "Idiosyncratic Dialects and Error Analysis", in International Review of Applied Linguistics, nº 9, 2, pp. 147-60.
Cresti, E., and M. Moneglia (2005) C-Oral-Rom: Integrated Reference Corpora for Spoken Romance Languages. Amsterdam-Philadelphia: John Benjamins. Studies in Corpus Linguistics, 13.
Fernández, S. (1997) Interlengua y análisis de errores en el aprendizaje del español como lengua extranjera. Edelsa: Grupo Didascalia
Granger, S. (2003) "Error-tagged Learner Corpora and CALL: a promising synergy", CALICO Journal, 20 (3), pp. 465-480. Available at: https://www.calico.org/html/article_289.pdf
James, C. (1998) Errors in Language Learning and Use. Exploring Error Analysis. London/New York: Longman. Applied Linguistics and Language Study Series.
Mitchell, R., L. Domínguez, Mª. Arche, F. Myles, and E. Marsden (2008) "SPLLOC: A new database for Spanish second language acquisition research". In L. Roberts, F. Myles, and A. David (eds.) EuroSLA Yearbook, 8, pp. 287-304. Amsterdam/Philadelphia: John Benjamins.
Myles, F. (2005) "Interlanguage corpora and second language acquisition research". Second Language Research, 21 (4), pp. 373-391.
Nicholls, D. (2003) "The Cambridge Learner Corpus – error coding and analysis for Lexicography and ELT". In Archer et al. (eds) Proceedings of the Corpus Linguistics 2003 Conference (CL2003). Lancaster University: University Centre for Computer Corpus Research on language, pp. 572-581. Available at: http://ucrel.lancs.ac.uk/publications/CL2003/papers/nicholls.pdf
Vázquez, G. (1999) Errores, ¡sin falta!. Madrid: Edelsa
10. Didactic guide
Please, contact the following email address if you are interested in the didactic guide of the learner corpus:
leonardo (dot) campillos (@) uam (dot) es
leonardo (dot) campillos (@) gmail (dot) com
Click here to download an abridged sample of the contents.
12. Contact
leonardo #dot# campillos $at$ uam #dot# es
leonardo #dot# campillos $at$ gmail #dot# com
13. Acknowledgements
This project was founded by the Regional Ministry of Education of the Madrid Regional Government, and the European Social Fund (ESF) (PhD grant).

![]()
I am kindly grateful to all the students who participated in the interviews, as well as to all the revisers of the transcriptions.
This search interface was developed thanks to a research stay in the School of Computing at Dublin City University. I thank sincerely to Dr. Monica Ward and to the research team at the National Center for Language Technology for the help received.
I have to thank also Dr. José Mª. Guirao (Universidad de Granada) and Antonio Pastor Cuevas (Universidad Autónoma de Madrid) for helping in the installation of the tool.



